
指令微调(Instruction Tuning)
指令微调(Instruction Tuning)是指使用自然语言形式的数据对预训练后的大语言模型进行参数微调,这一术语由谷歌研究员在2022年的一篇ICLR论文中正式提出[1]。在另外一些参考文献中,指令微调也被称为有监督微调(Supervised Fine-tuning)[2] 或多任务提示训练(MultitaskPromptedTraining)[3]。指令微调过程需要首先收集或构建指令化的实例,然后通过有监督的方式对大语言模型的参数进行微调。经过指令微调后,大语言模型能够展现出较强的指令遵循能力,可以通过零样本学习的方式解决多种下游任务。
🏔️指令数据的构建
一般来说,一个经过指令格式化的数据实例包括任务描述(也称为指令)、任务输入-任务输出以及可选的示例。
⛰️基于现有的NLP任务数据集构建
学术界围绕传统NLP任务(如机器翻译、文本摘要和文本分类等)发布了大量的开源数据集合,这些数据是非常重要的监督学习数据资源,可以用于指令数据集的构造。通常来说,这些NLP数据集都包括输入和输出两个主要部分。
例如,在中英翻译任务中,输入是“大语言模型已经成为机器学习的一个重要研究方向”,而相应的输出则是“Large language models have become one important research direction for machine learning”。
为了生成指令化的训练数据,一个非常关键的步骤就是为上述的“输入-输出”对数据添加任务描述信息,用于指导模型去理解任务目标以及相关信息。在上述的例子中,可以向中译英的翻译数据集中添加指令, 例如“请把这个中文句子翻译成英文”。通过上述操作,就可以将一个NLP任务的数据实例全部通过自然语言形式进行表达,进而数据实例可以被用于大语言模型的指令微调。
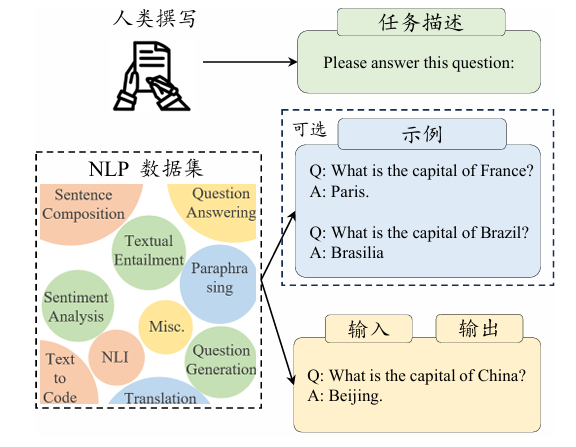
为了更好地标注NLP指令微调数据,研究 人员开发了众包平台PromptSourcehttps://github.com/bigscience-workshop/promptsource,它能够高效地支持标注人员为不同数据集创建、共享及验证任务描述。
🌋基于日常对话数据构建
尽管通过指令格式化已有的NLP数据集能够获得大量的指令数据实例,但是这些数据的多样性比较局限,与人类的真实需求也不能很好匹配。为此,研究人员开始使用用户在日常对话中的实际需求作为任务描述。例如,InstructGPT[2]将用户提交给OpenAI API的查询作为任务描述。由于这些用户查询源自于真实应用场景,均采用自然语言形式进行表达,因此特别适合大模型学习指令跟随能力。为了进一步增加任务的多样性,OpenAI还雇佣标注者创作更多的真实生活任务,包括开放式生成、开放式问答、头脑风暴等任务,然后由另一组标注者来回答这些问题作为输出。OpenAI最终将指令(用户真实查询或者人工标注的任务)和期望的输出(人工编写的答案)配对作为一个训练实例。但是,OpenAI没有对外开放所使用的指令数据。
🗻基于合成数据构建
Self-Instruct ——-> Yizhong Wang et al. “Self-Instruct: Aligning Language Model with Self Generated In structions”. In: arXiv preprint arXiv:2212.10560 (2022).
Evol-Instruct ——-> Can Xu et al. “WizardLM: Empowering Large Language Models to Follow Complex In structions”. In: arXiv preprint arXiv:2304.12244 (2023).
🏖️指令微调的训练策略
🏜️优化设置
指令微调中的优化器设置(AdamW或Adafactor)、稳定训练技巧(权重衰减和梯度裁剪)和训练技术(3D并行、ZeRO和混合精度训练)都与预训练保持阶段一致,可以完全沿用。
不同之处:
- 目标函数. 预训练阶段通常采用语言建模损失,优化模型在每一个词元上的损失。而指令微调可以被视为一个有监督的训练过程,通常采用的目标函数为序列到序列损失,仅在输出部分计算损失,而不计算输入部分的损失。
- 批次大小和学习率.考虑到预训练阶段已经学习到了能够展现较好性能的模型参数,指令微调阶段通常只需要使用较小的批次大小和学习率对模型进行小幅度的调整。例如InstructGPT(175B)微调的批次大小为8,学习率恒定为5.03×10−6;Alpaca (7B) 微调的批次大小为128,学习率预热到2×10−5,然后采用余弦衰减策略。
- 多轮对话数据的高效训练.对于一个多轮对话数据,通常的训练算法是将其拆分成多个不同的对话数据进行单独训练。为了提升训练效率,可以采用特殊的掩码机制来实现多轮对话数据的高效训练。在因果解码器架构中,由于输入输出没有明显的分界,可以将所有一个对话的多轮内容一次性输入模型,通过设计损失掩码来实现仅针对每轮对话的模型输出部分进行损失计算,从而显著减少重复前缀计算的开销。
🏝️数据组织策略
平衡数据分布:最常见的方法是样本比例混合策略,即把所有数据集进行合并,然后从混合数据集中等概率采样每个实例。例如,研究者建议混合使用NLP任务数据(如FLANv2)、对话数据(如ShareGPT)和合成数据(如GPT4-Alpaca),来进行大模型的指令微调。
多阶段指令数据微调:首先使用大规模NLP任务指令数据对模型进行微调,然后再使用相对多样的日常对话指令和合成指令进一步微调。为了避免能力遗忘问题,可以在第二阶段中添加一些NLP指令数据。
结合预训练数据与指令微调数据:为了使得微调过程更加有效和稳定,可以在指令微调期间引入预训练数据和任务,这可以看作是对于指令微调的正则化。
🏛️参数高效的模型微调
通过指令微调,大语言模型能够更好地学习遵循和执行人类指令。然而,由于大语言模型的参数量巨大, 进行全参数微调(需要较多的算力资源开销)在本节中,我们将讨论如何针对大语言模型进行参数高效微调(Parameter-efficient Fine-tuning),也称为轻量化微调 (Lightweight Fine-tuning)。在现有文献中,参数高效微调[4,5,6] 是一个重要的 研究方向,旨在减少需要训练的模型参数量,同时保证微调后的模型性能能够与全量微调的表现相媲美。下面将首先介绍常用于Transformer架构的参数高效微调方法,然后以LoRA微调方法为例介绍参数高效微调的代码实现。
🏘️低秩适配微调方法
🏬LoRA基础
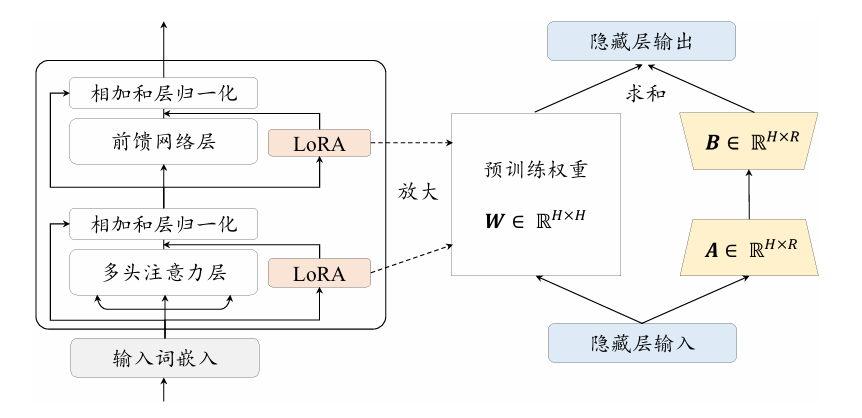
大语言模型中包含大量的线性变换层,其中参数矩阵的维度通常很高。研究人员[6]发现模型在针对特定任务进行适配时,参数矩阵往往是过参数化(Over-parametrized)的,其存在一个较低的内在秩。为了解决这一问题,LoRA[6] 提出在预训练模型的参数矩阵上添加低秩分解矩阵来近似每层的参数更新,从而减少适配下游任务所需要训练的参数。给定一个参数矩阵𝑾,其更新过程可以一般性地表达为以下形式:
$$ W = W_0 +ΔW $$其中,$W_0$是原始参数矩阵,Δ𝑾是更新的梯度矩阵。LoRA的基本思想是冻结原始矩阵$W_0 ∈ R^{H \times H}$,通过低秩分解矩阵$A ∈ R^{H \times H}$和$B ∈ R^{H \times H}$来近似参数更新矩阵$Δ𝑾 = A·B^T$,其中𝑅≪𝐻是减小后的秩。在微调期间,原始的矩阵参数$W_0$不会被更新,低秩分解矩阵𝑨和𝑩则是可训练参数用于适配下游任务。在前向传播过程中,原始计算中间状态$h=W_0·x$的公式修改为:
$$ h = W_0·x + A·B^T·x $$在训练完成后,进一步将原始参数矩阵$W_0$和训练得到的权重𝑨和𝑩进行合并:$W = W_0 + A·B^T$,得到更新后的参数矩阵。因此,LoRA微调得到的模型在解码过程中不会增加额外的开销。
🏦LoRA变种
在原始的LoRA实现中,每个低秩矩阵的低秩参数𝑅都被设置为固定且相同的数值,并且在训练过程中无法进行调整,这种设定忽略了不同的秩在微调任务中可能产生的差异化影响。因此,通过这种方式训练得到的低秩矩阵往往并非最优解。AdaLoRA[7]讨论了如何更好地进行秩的设置。它引入了一种动态低秩适应技术,在训练过程中动态调整每个参数矩阵需要训练的秩同时控制训练的参数总量。具体来说,模型在微调过程中通过损失来衡量每个参数矩阵对训练结果的重要性,重要性较高的参数矩阵被赋予比较高的秩,进而能够更好地学习到有助于任务的信息。相对而言,不太重要的参数矩阵被赋予比较低的秩,来防止过拟合并节省计算资源。尽管LoRA能够有效地节省显存,但对于参数规模达到上百亿级别的模型而言,其微调所需的成本仍然相当高昂。QLoRA[8]将原始的参数矩阵量化为4比特,而低秩参数部分仍使用16比特进行训练,在保持微调效果的同时进一步节省了显存开销。根据上一小节的分析,对于给定参数量为𝑃的模型,QLoRA微调所需要的显存由LoRA微调所需要的2𝑃进一步下降为0.5𝑃。因此通过QLoRA技术,可以在一张A6000(48GB)的GPU上微调65B的模型,接近16比特模型微调的性能。
🏡其他高效微调方法
适配器微调、前缀微调、提示微调
参考文献
[1]. Jason Wei et al. “Finetuned Language Models are Zero-Shot Learners”. In: ICLR. 2022.
[2]. Long Ouyang et al. “Training language models to follow instructions with human feed back”. In: arXiv preprint arXiv:2203.02155 (2022).
[3]. VictorSanhetal. “Multitask Prompted Training Enables Zero-Shot Task Generalization”. In: ICLR. 2022.
[4]. XiangLisa Li and Percy Liang. “Prefix-Tuning: Optimizing Continuous Prompts for Gen eration”. In: ACL. 2021.
[5]. Brian Lester, Rami Al-Rfou, and Noah Constant. “The Power of Scale for Parameter Efficient Prompt Tuning”. In: EMNLP. 2021.
[6]. EdwardJ.Huetal. “LoRA:Low-RankAdaptation of Large Language Models”. In: ICLR. 2022.
[7]. Qingru Zhang et al. “Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning”. In: arXiv preprint arXiv:2303.10512 (2023).
[8]. TimDettmersetal.“QLoRA:EfficientFinetuningofQuantizedLLMs”.In:arXivpreprint arXiv:2305.14314 (2023).