
🎄提示学习
经过预训练、指令微调和人类对齐后,我们接下来讨论如何通过提示学习方法来有效地使用大语言模型解决实际任务。目前常用的方法是设计合适的提示(Prompting),通过自然语言接口与大模型进行交互。在现有研究中,任务提示的设计主要依靠人工设计和自动优化两种策略来实现。为了更好地 解决未见过的任务,一种典型的提示方法是上下文学习(In-contextLearning,ICL),它将任务描述与示例以自然语言文本形式加入到提示中。此外,思维链提示(Chain-of-Thought, CoT)作为一种增强技术,将一系列中间推理步骤加入到提示中,以增强复杂推理任务的解决效果。
🎆基础提示
因为大语言模型的微调代价较高,基于自然语言的提示方法已经成为了使用大语言模型解决下游任务的主要途径。由于提示的质量在很大程度上会影响大语言模型在特定任务中的表现,因此一系列工作深入研究了通过人工设计或自动优化的方法来生成合适的任务提示。
🎇人工提示设计
针对特定任务设计合适的任务提示,这一过程被称为“提示工程”(Prompt Engineering)。
🧨关键要素
一般而言,针对大语言模型的提示设计需要考虑四个关键要素,即任务描述、输入数据、上下文信息和提示策略。
- 任务描述.任务描述部分展示了大语言模型应当遵循的具体指令。一般来说,用户应该使用清晰的、具体的表达来描述任务目标。进一步,某些特定任务还需要对于输入或输出的格式进行更详细的说明,可以使用关键词或者特殊符号来强 调特殊设置以指导大语言模型更好地完成任务。
- 输入数据. 通常情况下,用户可以直接使用自然语言描述输入数据的内容。对于特殊形式的输入数据,则需要采用合适的方法使其能够被大语言模型读取与理解。例如,对于结构化数据(如知识图谱、表格等),通常使用线性化方法将其转换为易于处理的文本序列[264]。此外,由于结构化数据具有较好的组织形式,可以使用编程代码中的数据结构进行存储表示,将结构化数据中的属性表示为数据结构中的变量。基于代码表示的结构化数据可以使用外部工具(如程序执行器)进行准确地读取。
- 上下文信息. 除了任务描述和输入数据外,上下文信息对某些特定任务也非常重要。例如,搜索引擎可以为开放问答任务提供参考文档,可以通过将检索到的参考文档以上下文信息的形式引入提示作为大语言模型的输入。在引入外部信息时,需要对于这些信息进行合适的格式化,以加强大语言模型对它们的利用。此外,上下文学习中的任务示例数据也有助于提升大语言模型处理复杂任务的能力,大模型可以通过这些示例数据学习任务目标、输出格式以及输入和输出之间的映射关系。
- 提示策略. 针对不同的大语言模型设计合适的提示策略对于激发模型解决特定任务的能力非常重要。在某些情况下,添加特定的前缀或后缀有助于引导大语言模型解决复杂任务。例如,使用前缀“让我们一步一步地思考”可以激发大语言模型的逐步推理能力,而使用前缀“你是这项任务(或这个领域)的专家”可以提高大语言模型在某些特定任务(或领域)中的表现。此外,对于对话式的大语言模型(例如ChatGPT),由于其使用了大量对话数据进行训练,因此更合适的做法是将提示拆分为多个子任务提示,以多轮对话的方法逐步输入给大语言模型。
✨自动提示优化
人工设计提示虽然比较直接,但是需要耗费较多的人工成本,同时要求设计人员具有丰富的提示工程经验。此外,大语言模型对于提示设计比较敏感,人工设计的提示有时很难获得最优的效果,还可能导致任务性能的下降。需要注意的是,由于大语言模型参数量巨大,并且很多工作机制已经与传统预训练模型有着较大的差异,许多提示优化方法已经不再适用于大语言模型。
🎉离散提示优化
离散提示通常是由一系列自然语言词元组成的完整句子表达(如“请根据提供的检索信息回答下列问题”)。然而,在离散的词元空间中进行组合搜索,不仅时间复杂度高,而且可能导致非最优的搜索结果。下面将介绍四种常见的离散提示优化方法,能够提升离散任务提示的有效性与搜索效率。
- 基于梯度的方法. 这类方法通过梯度更新技术以最大化模型的似然分数来优化离散提示的搜索过程。一种早期的代表性方法[1]使用梯度引导技术,首先将提示初始化为一系列“[MASK]”标记,然后迭代地将提示中的词元替换为词典中的其他词元,通过词元替换产生的对数似然变化来近似估计梯度,进而为提示的每个位置贪心搜索出最佳的词元。由于该方法对提示的每个位置都进行所有候选词元的替换和梯度评估,因此需要模型进行多次前向和后向计算,导致搜索过程的效率较低。为了改进搜索效率,可以将离散词元转化为连续嵌入表示(又称为“软词元”),使用梯度直接对连续嵌入参数进行优化,最后将每个连续嵌入映射为词典中最邻近的离散词元。
- 基于强化学习的方法. 为了实现更有效的离散词元选择,另一种解决方法是将离散提示优化问题转换为强化学习问题,并使用强化学习算法进行求解。具体来说,可以将预训练语言模型作为强化学习中的策略网络并依次生成提示中的词元。在提示生成结束之后,策略网络可以获得任务特定的奖励信号,该奖励信号可通过强化学习算法用于策略网络参数的训练。在实践中,可以设计不同类型的奖励信号,比如真实标签与基于提示的预测标签是否一致、生成文本与给定条件的匹配程度。在最后的测试阶段,基于训练好的策略网络,可以采用贪心搜索策略来生成任务提示中的每个词元。
- 基于编辑的方法. 这类方法主要关注如何通过编辑现有的提示来改进模型的性能,通常是基于模型在目标任务上的表现来判断提示的好坏。它特别适用于无法直接访问模型内部状态(如梯度)的情况,例如只能通过API调用的模型。在这类方法中,通常需要事先定义好编辑操作,然后迭代地对提示进行修改,直至达到最大迭代轮次或者模型最佳性能。提示的关键要素包括任务描述、输入数据、上下文信息和提示策略。因此,常用的提示编辑操作有修改任务描述、添加或删除上下文任务示例、调整输入到输出的标签映射器(例如可以使用“positive/negative”或者“正/负”表示二分类)等。此外,提示编辑操作也可以根据不同的场景或者需求进行设计,以适配下游具体任务。整体流程可以概述如下:基于预定义的编辑操作,在现有提示的基础上修改得到新提示,并输入至模型得到目标任务上的表现,根据表现筛选出合适的提示。由于上述过程可能需要迭代进行,可以只选择少量测试样例来评估模型表现,以减少计算开销。
- 基于大语言模型的方法. 由于大语言模型具有通用的任务能力,因此可以将提示优化看作一个待求解的任务,进而直接使用大语言模型作为提示生成器来生成或改进提示[2,3]。基于大语言模型的自动提示生成框架将提示优化过程看作是一个由大语言模型指导的黑盒优化问题。该框架首先利用提示生成模型(用于生成提示指令的大语言模型)基于少量上下文示例生成一批候选的任务指令。随后,使用“目标模型”(用于下游测试的大语言模型)对这些候选指令在目标任务上的表现进行逐一评估。在评估过程中,可以采用模型困惑度或任务准确率作为衡量指令质量的指标。上述过程可以通过基于蒙特卡洛搜索的多轮优化策略进行扩展。在每一轮迭代中,根据模型表现对候选指令进行筛选得到高评分指令,并利用大语言模型生成与高评分指令相似的新指令,从而扩展候选指令集。迭代完成后,选择模型表现最佳的候选指令作为最终使用的提示。然而,上述方法没有充分考虑提示的整个历史改进轨迹,因此可能在提示搜索过程中陷入局部最优或者产生效果震荡,无法生成更好的提示。为了解决这一问题,可以将所有改进的历史提示及其分数纳入提示优化过程,以指导大语言模型逐步生成更好的新提示。
🎊连续提示优化
与离散提示不同,连续提示由一组连续空间中的嵌入向量组成,可以根据下游任务的损失直接通过梯度更新进行优化。值得注意的是,已有连续提示优化的工作主要是基于预训练语言模型开展的,由于大语言模型参数量巨大,连续提示受到的关注较为有限。已有的连续提示优化研究通常依赖于有监督学习方法。当数据稀缺的情况下,还可以采用迁移学习方法来缓解目标任务标注数据不足的问题。
- 监督学习方法. 这类方法将连续提示向量视为可训练的模型参数,基于下游任务数据,通过最小化交叉熵损失来优化连续提示。Prefix-tuning [4] 会在语言模型的每个Transformer 层预置一串前缀(即一组可训练的连续向量),而Prompt-tuning[5]只会在输入层加入可训练的提示向量。 通过固定语言模型的大规模参数而只微调这些连续的提示向量,可以有效节省训练所需要的参数量。然而,这些提示优化方法通常与输入无关,缺乏对于输入语义的充分考虑。
- 迁移学习方法. 有监督学习方法通常需要充足的训练数据来学习最优的任务提示,很难在数据稀缺场景下获得较好的模型性能。为了解决这个问题,基于提示的迁移学习方法首先为若干个具有代表性的源任务学习一个所有任务共享的连续提示,然后使用该提示初始化目标任务的提示,这可以为下游任务的提示优化提供良好的初始点。然而,这种方法存在一定的局限性,它在解决目标任务的所有实例时都使用了相同提示,而即使是一个精心优化过的提示也未必适合所有的任务实例。为了解决这一问题,可以为每个源任务独自学习任务特定的连续提示(而不是所有源任务共享),在解决目标任务的实例时,可以采用注意力机制等方式学习目标实例与每个源任务提示的相关性权重系数,对若干个源任务的提示向量进行加权组合,将组合后的新提示(为连续向量形式)用于帮助模型解决当前任务实例。
🎋上下文学习
在GPT-3的论文[6]中,OpenAI研究团队首次提出上下文学习(In-context learning,ICL)这种特殊的提示形式。目前,上下文学习已经成为使用大语言模型解决下游任务的一种主流途径。下面将详细介绍这一提示方法。
🎍上下文学习的形式化定义
根据GPT-3论文中所给出的描述[6],上下文学习使用由任务描述和(或)示例所组成的自然语言文本作为提示。图10.1展示了上下文学习的提示构建过程。首先,通过自然语言描述任务,并从任务数据集中选择一些样本作为示例。其次,根据特定的模板,将这些示例按照特定顺序组合成提示内容。最后,将测试样本添加到提示后面,整体输入到大语言模型以生成输出。基于任务描述以及示例信息,大语言模型无需显式的梯度更新即可识别和执行新的任务。
形式上,我们使用𝐷𝑘={𝑓(𝑥1,𝑦1),…, 𝑓(𝑥𝑘,𝑦𝑘)}来表示由𝑘个样本构成的一组示例数据,其中𝑓(𝑥𝑘,𝑦𝑘)是一个函数,负责将第𝑘个任务样本转换为自然语言提示。给定任务描述𝐼、示例𝐷𝑘以及新的输入𝑥𝑘+1,大语言模型生成答案ˆ 𝑦𝑘+1的过程可以通过下面的公式来表述:
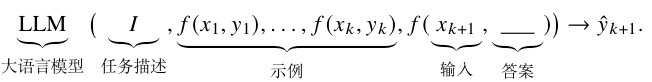
值得一提的是,上下文学习与指令微调之间存在着紧密的联系,因为它们都涉及将任务或样本转化为自然语言形式供大语言模型进行处理。在原始的GPT-3论文中,作者将上下文学习的提示定义为任务描述和示例的组合,这两部分均为可选。按照这个定义,如果大语言模型仅通过任务描述(即任务指令)来解决未见过的任务,也可以被看作是上下文学习的一种特例。两者的主要区别是,指令微调需要对大语言模型进行微调,而上下文学习仅通过提示的方式来调用大语言模型解决任务。此外,指令微调还可以有效提升大语言模型在执行目标任务时的上下文学习能力,尤其是在零样本场景下(即仅依赖任务描述而无需额外的示例)。
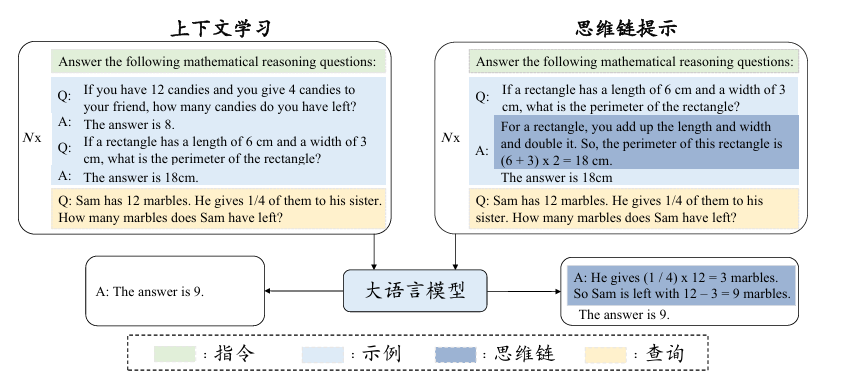
🎁思维链提示
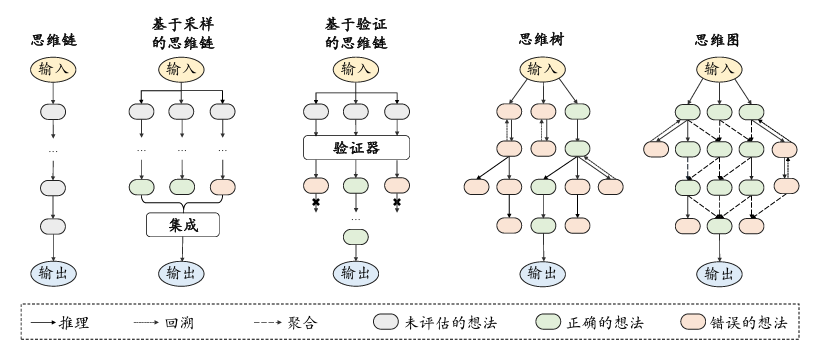
思维链提示[7,8]是一种高级提示策略,旨在增强大语言模型在各类复杂推理任务上的表现。常见的推理任务包括算术推理[9]、常识推理[9]以及符号推理[7]等多种任务。与上下文学习方法仅使用⟨输入,输出⟩二元组来构造提示不同,思维链提示进一步融合了中间的推理步骤来指导从输入到输出的推理过程。下图展示了一个思维链提示的具体例子。
🎑参考文献
[1]. Taylor Shin et al. “AutoPrompt: Eliciting Knowledge from Language Models with Auto matically Generated Prompts”. In: EMNLP. 2020.
[2]. Yongchao Zhou et al. “Large Language Models are Human-Level Prompt Engineers”. In: ICLR. 2023.
[3]. Chengrun Yang et al. “Large Language Models as Optimizers”. In: arXiv preprint arXiv: 2309.03409 (2023).
[4]. XiangLisa Li and Percy Liang. “Prefix-Tuning: Optimizing Continuous Prompts for Gen eration”. In: ACL. 2021.
[5]. Brian Lester, Rami Al-Rfou, and Noah Constant. “The Power of Scale for Parameter Efficient Prompt Tuning”. In: EMNLP. 2021.
[6]. TomB.Brown et al. “Language Models are Few-Shot Learners”. In: NeurIPS. 2020.
[7]. JasonWeietal. “Chain of Thought Prompting Elicits Reasoning in Large Language Mod els”. In: arXiv preprint arXiv:2201.11903 (2022).
[8]. Zheng Chu et al. “A Survey of Chain of Thought Reasoning: Advances, Frontiers and Future”. In: arXiv preprint arXiv:2309.15402 (2023).
[9]. Shen-Yun Miao, Chao-Chun Liang, and Keh-Yih Su. “A Diverse Corpus for Evaluating and Developing English Math Word Problem Solvers”. In: ACL. 2020.
[10]. AlonTalmoret al. “CommonsenseQA: A Question Answering Challenge Targeting Com monsense Knowledge”. In: NAACL-HLT. 2019.