
文献阅读
每周都完不成上次的任务,杂事太多了,尽快完成:
Detecting formal thought disorder by deep contextualized word representations
竟然要收费,不看了,让gpt给讲一下
这篇论文《通过深度上下文化词表示检测形式思维障碍》研究了如何使用深度学习中的上下文词嵌入模型(如ELMo)来检测精神疾病患者的形式思维障碍(Formal Thought Disorder, FTD)。FTD是一种影响语言表达和思维逻辑的精神疾病症状,常见于精神分裂症患者。
论文主要利用深度上下文化词嵌入模型,如ELMo,通过生成词在句子中的嵌入表示,捕捉语境中词的多义性和丰富的语义信息。研究团队通过分析患者的语言数据,构建模型来区分正常语言与存在思维障碍的语言表达,从而实现自动化的FTD检测。
研究的核心贡献是使用更复杂的语义表示(如上下文化词嵌入)来解决传统方法无法有效处理的词义歧义问题。
Distributed Representations of Words and Phrases and their Compositionality
《Distributed Representations of Words and Phrases and their Compositionality》是由Mikolov等人在2013年提出的一篇重要论文,介绍了Word2Vec模型的改进和创新。这篇文章主要讨论了如何通过分布式词表示(distributed word representations)更好地捕捉单词和短语的语义信息,并且提出了两种核心模型:CBOW(Continuous Bag of Words) 和 Skip-gram。
这篇论文的主要贡献包括:
- Skip-gram和CBOW模型:论文提出了两种用于生成词向量的架构。Skip-gram模型的目标是根据一个词预测其上下文,而CBOW模型则根据上下文词来预测目标词。这两种模型能够有效地捕捉单词之间的语义关系。
- 层次Softmax和负采样:为了提高训练大规模语料库的效率,作者引入了层次Softmax和**负采样(negative sampling)**技术,这大幅降低了模型的计算复杂度,使得大规模训练变得可行。
- 词和短语的组合性:论文不仅处理了单词的表示,还处理了短语的表示,通过数据驱动的方式将多词短语映射为词向量,捕捉更复杂的语义结构。
- 向量运算反映语义关系:Word2Vec生成的词向量能够通过简单的向量运算表达词语之间的关系。例如,向量运算
vec("King") - vec("Man") + vec("Woman") ≈ vec("Queen")说明了这种分布式表示在捕捉语义关系上的强大能力。
LLM BOOK
找到一本书,准确的来说是一个github仓库,组织者把近些年的LLM相关的东西都整进去了,好全,写的真好,库库看吧那就
第一部分 背景与基础知识
语言模型的发展历程(P16)
LLM大语言模型那肯定是从LM语言模型来的,语言模型的发展又经历了:
- 统计语言模型(StatisticalLanguageModel, SLM)
- 神经语言模型(NeuralLanguageModel,NLM)
- 预训练语言模型(Pre-trainedLanguageModel,PLM)
- 大语言模型(LargeLanguageModel, LLM)
LLM的特点(P19)
- 具有较为丰富的世界知识
- 具有较强的通用任务解决能力
- 具有较好的复杂任务推理能力
- 具有较强的人类指令遵循能力
- 具有较好的人类对齐能力
- 具有可拓展的工具使用能力
大语言模型对于产业应用带来了变革性的技术影响,将会催生一个基于大语言模型的应用生态系统。
第二部分 预训练
大语言模型的第一个训练阶段是预训练,预训练语料的规模和质量对于提升大语言模型的能力至关重要。
数据来源
通用文本数据和专用文本数据。通用文本数据涵盖了网页、书籍和对话文本等。由于通用文本数据规模较大、多样性强且易于获取,大多数大语言模型都会收集大量的通用文本数据,以增强其语言建模能力。此外,为了进一步提升大语言模型在特定专业任务上的表现,人们还将预训练语料的范围扩展至更专业的数据集,如多语数据、科学数据和代码数据等。
通用文本数据
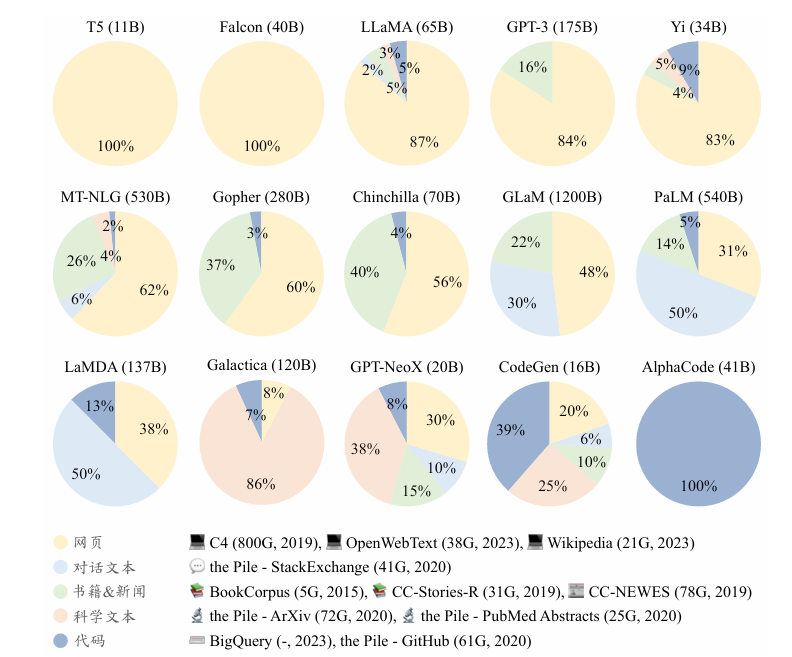
专用文本数据
多语文本、 科学文本、代码。

数据预处理
构建并使用系统化的数据处理框架(如开源库Data-Juicer)
具体操作(P74)
附录
softmax是啥?
Softmax是一种常用的函数,特别是在多分类任务中,用来将一个向量中的元素转换为0到1之间的概率分布。其核心作用是:
-
将实数映射为概率分布:Softmax 接受一个实数向量,输出一个与输入维度相同的向量,其中每个元素的值表示该元素作为某个类别的概率,且这些概率的和为1。这样就可以根据这些概率来进行分类预测。
-
公式:Softmax 函数的定义如下:
$$ \text{Softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{n} e^{z_j}} $$其中,\( z_i \) 是输入向量中的某个元素,\( e^{z_i} \) 是该元素的指数值,分母是所有输入元素的指数值的和。这个函数将每个 \( z_i \) 映射为一个在 \( (0,1) \) 之间的概率,并且所有输出的概率之和为1。
-
作用机制:
- 指数放大效果:Softmax 函数通过对输入值取指数(\( e^x \)),会将较大的输入值放大更多,而较小的值则被进一步压缩,突出更大的概率。
- 归一化:Softmax 保证所有输出的概率之和为1,符合概率的定义。
-
应用场景:在神经网络的最后一层,特别是分类任务中,Softmax 常用于多类分类问题,比如在自然语言处理(NLP)中的词分类、图像识别中的对象分类等。它将网络的输出转化为易于理解的概率值,帮助模型决定输入属于哪个类别。
举例
假设我们有一个模型输出三个值 \( [2.0, 1.0, 0.1] \),通过 Softmax 转换后得到的结果是大约 \( [0.71, 0.26, 0.03] \),其中最大的值0.71表示模型认为输入属于第一个类别的概率最大。
简言之,Softmax 是一种将输出转换为概率分布的工具,特别适合多分类问题的场景。
看了半天论文,感觉没有一个时间线很难受,不清楚那些论文之间的关系,问问gpt:
基础概念与理论
先掌握大模型背后的基本理论,这些知识是理解后续论文的基础:
- 语言模型的基础:
- 经典论文:《Attention Is All You Need》(Transformer)
- 相关概念:自注意力机制、序列到序列模型、词嵌入(如Word2Vec、GloVe)
- 自回归模型与自编码器:
- GPT 系列(GPT, GPT-2, GPT-3)的原理和应用
- BERT 及其衍生模型的预训练与微调方式
- 扩展学习与生成式任务:
- 《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
- 生成式预训练模型的设计与任务应用(如文本生成、机器翻译)
模型的训练与优化
学习如何高效地训练大模型,并且了解模型的优化技术:
- 微调与参数高效训练:
- Efficient Fine-Tuning Techniques for Large Models: Adapter, LoRA 等
- 探索模型压缩技术(知识蒸馏、量化、剪枝等)
- 对比学习与自监督学习:
- 《SimCLR》、《MoCo》 等代表性论文,理解对比学习在大模型中的应用
模型对齐与安全
在大模型发展过程中,模型对齐(alignment)和伦理问题变得越来越重要:
- 模型对齐与价值观嵌入:
- 《InstructGPT: Training language models to follow instructions with human feedback》
- RLHF(强化学习通过人类反馈)等对齐策略
- 模型安全与公平性:
- 探讨模型偏见问题以及在实际应用中的安全隐患
视觉-语言模型与多模态模型
学习大模型在跨模态任务中的应用,比如视觉-语言任务:
- CLIP(Contrastive Language-Image Pretraining):理解图像和文本共同表征的训练方法
- DALL-E、Stable Diffusion:生成式视觉任务的模型设计与应用
- 视觉语言对话系统:如《Visual ChatGPT》
前沿研究与新趋势
在深入理解基本模型后,可以关注大模型领域的前沿研究方向:
- 大模型与知识图谱的结合:如何将知识图谱融入语言模型
- 领域自适应模型:如何通过特定领域数据进行模型的进一步微调
- 检索增强生成(RAG):如《RAG: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》
实战应用与开源框架
- 阅读开源项目中的技术文档,参与开源项目(如Hugging Face的模型库)
- 学习如何应用大模型解决实际问题,并尝试训练和微调自己的模型
这样,你可以从基础概念、模型训练到前沿研究和实战应用,逐步深入,既能掌握理论又能结合实践。这个过程可以帮助你筛选出重要的论文和研究方向。
对齐是什么意思?
在大型语言模型(LLM)中,“对齐”通常指的是模型的输出与人类意图或价值观的匹配程度。具体来说,它涉及确保模型在生成文本时能够产生符合人类期望的、有益的和安全的内容。对齐的目标是减少模型生成有害、误导或不准确的信息。
对齐可以通过多种方法实现,包括:
-
训练数据的选择和清洗:使用高质量的数据集进行训练,确保模型接触到的内容符合人类的价值观和期望。
-
强化学习:利用人类反馈来微调模型,使其在生成内容时更符合人类的意图。
-
安全性和伦理性评估:在模型发布之前,对其输出进行评估,以识别和修正潜在的偏见或有害内容。
通过这些方法,可以提高模型在特定任务或应用场景中的可靠性和安全性。
arXiv 论文是什么?
arXiv 是一个开放获取的电子预印本存档,主要用于科学研究领域,特别是在物理学、数学、计算机科学、统计学、金融学、生物学和其他相关学科。研究者可以在 arXiv 上免费上传和分享他们的研究论文,通常是在正式出版之前的版本。
arXiv 的特点包括:
-
快速发布:研究者可以迅速分享他们的研究成果,而不必等待同行评审和正式出版的过程。
-
开放获取:任何人都可以访问和下载论文,无需订阅或支付费用。
-
广泛的学科覆盖:涵盖多个领域,促进跨学科的交流和合作。
-
社区反馈:研究者可以在正式发表之前收到来自社区的反馈,帮助他们改进论文。
arXiv 的论文通常以“预印本”的形式存在,因此它们可能尚未经过同行评审。这意味着在引用这些论文时,研究者需要谨慎,了解其可能的局限性。
在arXiv上发还未出版的论文不怕被别人剽窃成果吗?
在 arXiv 上发布未出版的论文确实存在被剽窃的风险,但研究者通常认为在 arXiv 上共享研究成果是有益的,原因如下:
-
时间戳和公开记录:一旦论文被上传到 arXiv,上传的时间戳可以作为知识产权的证明。这在某种程度上可以保护研究者的原创性。
-
学术社区的支持:arXiv 是一个活跃的学术社区,研究者通常会关注相关领域的论文,并且对剽窃行为持有负面态度。学术界普遍重视诚信,剽窃通常会受到严厉的谴责。
-
早期反馈:通过发布预印本,研究者可以获得来自同行的反馈,从而改进自己的工作。这也有助于在正式出版之前建立声誉。
-
增加曝光率:在 arXiv 上发布可以提高研究的可见性,吸引潜在合作者或资助者。
通用人工智能系统是什么?
通用人工智能系统(AGI, Artificial General Intelligence)指的是一种能够理解、学习和应用知识,完成任何人类所能完成的智力任务的人工智能系统。与当前的狭义人工智能(Narrow AI)相比,后者在特定任务或领域表现出色(如图像识别、自然语言处理等),AGI 的目标是实现一种更广泛的智能,具备跨领域的学习和适应能力。
AGI 的特点包括:
-
自主学习:能够从有限的数据中学习并推理,具备自我改进的能力。
-
多任务处理:能够在多个不同的领域和任务中表现出色,而不局限于特定的应用。
-
常识推理:具备理解和应用常识的能力,能够处理复杂的、不确定的环境。
-
灵活性和适应性:能够适应新情况和挑战,灵活地应对不同的环境和需求。
AGI 的发展仍然是一个前沿研究领域,目前尚未实现。许多研究者在探索如何构建这样的系统,同时也讨论其潜在的伦理和社会影响,例如对就业、隐私和安全的影响。
思考
随着看的东西多了,和使用chatgpt,我隐隐感觉到,由于chatgpt的语言模型主要是通过预测下一个最可能的词来生成文本,这一过程称为自回归生成(autoregressive generation)。导致gpt经常会顺着你的话去说,即有更小的概论去反对你的话,尽量让你说的话看起来正确,当然,如果你说的是:“太阳从西边升起”,那么他会义无反顾的反驳你。